Contents: Unsupervised learning algorithm —- K-means and Principal Component Analysis
Unsupervised learning allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don’t necessarily know the effect of the variables.
K-means algorithm
K-means clustering is the fisrt unsupervised algorithm that we are going to learn, it aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster.
Input:
- K — Number of clusters
- Training Set {}, where . Note that we don’t need the bias term here.
Cost function
Firstly let:
- = index of cluster (1, 2, .., K) to which example is currently assigned
- = cluster centroid k ( )
- = cluster centroid of cluster to which example has been assigned
Then the cost can be written as:
Random initialization
We initialize clusters by randomly pick K traning examples, then set equal to these examples. Formally:
Pick k distinct random integers from {1, .., m}, then set .
Optimizating objective
Next, in order to minimise the cost function, we find the appropriate values of through the following iteration:
Randomly initialize K cluster centroids
Repeat {
- for i = 1 to m
:= index of cluster centroid closest to , where . for k = 1 to K
:= average of points assigned to cluster k, namely:.}
The first for loop is the clusters assignment step, where it’s minimising J by reassigning ‘s to closest clusters, holding ‘s fixed, while the second for loop is minimising J by moving centroids, leaving unchanged. So the cycle continues until the algorithm converges to the global minimum, and… what if it’s a local minimum?
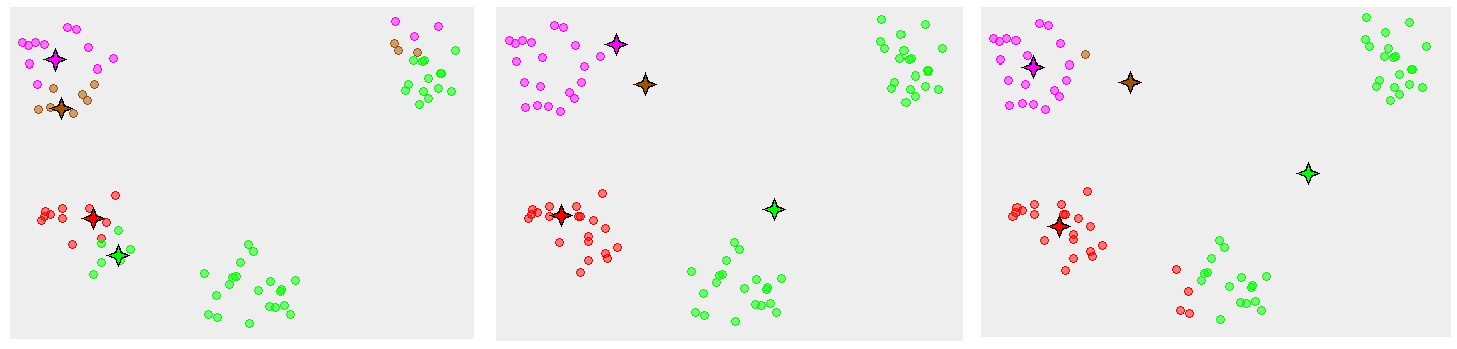
For above we see there are many case where the K-means gives unexpected results, one way to solve this is to rerun the algorithm many times with different initializations, a pseudo code looks like:
1 | for i = 1 to 100 { |
Remeber that when testing the cross validation set, make sure use PCA first, then
apply the algorithm.
Choosing the value of K
How many clusters? A hard question. It’s the most common case that people choose it manually, but here is a little trick that you might consider to use — the Elbow method

Consider the image above as a part of human body: the highest point is the shoulder, the lowest is the hand, and the point surrounded by red circle is the elbow. It’s suggested that we shall choose the elbow point to decide how many clusters to use, as all the marginal costs after this point become insignificant and so are unnecessary.
On the other hands, you sometimes may run K-means to get clusters to use for some later/downstream purpose (e.g. sizes of T-shirt — S,M,L or XS, S, M, L, SL?), and evaluate K-means based on a metric for how well it performs for that later purpose.
Principal Component Analysis
PCA is a powerful unsupervised algorithm that can reduce data from n dimensions(features) to k dimensions, I will introduce it directly by showing how it works:
Apply mean normalization and/or feature scaling to the dataset (important)
Compute the n × n “covariance matrix”:
- Computer the eigenvector U of the matric Σ:
- From the matrix U, select first k columns as , then get our example with new dimensions:
- Or if we want specific feature, just use
In matlab, we can get the eigenvectors and new example z as following:
1 | [U,S,V] = svd(Sigma); |
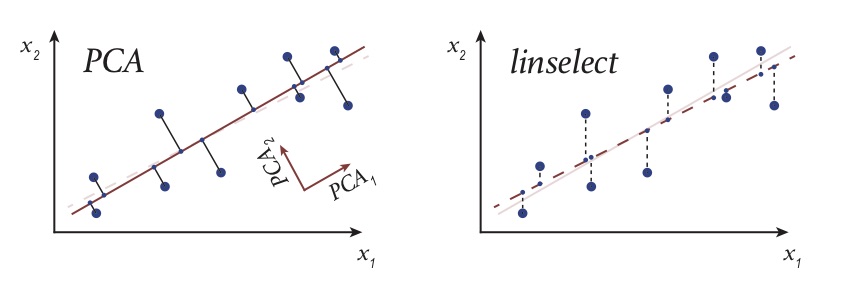
PCA VS. Linear Regression
These two algorithms looks somehow similar but actually different. PCA is trying to minimising the following:
While Linear Regression has a goal of minimising:
We can also see the difference from the graph below:
Choosing k (number of principal components)
When discussing PCA, rather than ask “what’s your value for k” , people would say “how many % of variance have you retained”. That means a strategy of choosing k by the following:
- Try PCA with k = 1
- Check if
- if the above holds, then exits with current value of k. Otherwise, continue the loop with k += 1
So we end up with the smallest possible value of k that retained 99% of variance, it’s totally fine to choose other number like 95% instead of 99%. Note that the formula above is the same as (1 - Coefficient of determination).
Moreover, we can obtain this value by using the matrix S provided by the function svd() used above:
1 | [U,S,V] = svd(Sigma); |
The S matrix will be a n by n matrix, and we have the procedure with exactly the same result:
Pick smallest value of k which makes 99% of variance retained:
Application
There are two main use of PCA:
Compression —- For the purpose of reducing memory/disk needed to store data, or in order to speed up learning algorithm.
Visualization —- Reduce from a large nummber to 2 or 3 dimensions helps to extract the information and is able to visualize to show potential relationship.
However, it’s not a good use of PCA to try to prevent overfitting. It is true that fewer features makes overfit less likely to happen, but the loss of information may worse the performance. Instead, it is more reasonable to use regularization to do so.