Contents: Support Vector Machine
BAD NEWS: Sadly, Couresara is no longer providing reading notes from this chapter and onwards for some reason (e.g. laze). That means I have to make the ENTIRE note by myself.
Week 7
Support Vector Machine
Cost function
The cost function for SVM is somehow similar to the one for logistic regression, such that we can get it by only editing a few things on the later one:
- replace and by and respectively:
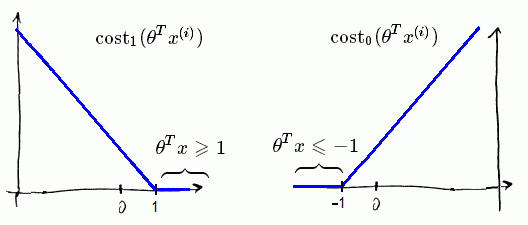
- multiply the whole function by m
- instead of multiply λ on the regularized term, we multiply a constant C on the data set terms (so that if C = , this edition has little effect)
So here is the brand new cost function:
And in order to minimise the cost function, we want .
SVM is a Large margin classifier, by this I mean the algorithm is trying to seek a decision boundary such that the distances between different groups of observations and the oundary are maximised. The following explain this mathematically:
Firstly, it can be shown that , where is the projection of onto , the graph below shows two examples of :

Remeber that we are trying to minimise the cost function. Using the substitution above our goal is make , that is to maximise by manipulating θ. The graph below shows a much better choice than the last one:

On the other hand, making large allows us to make θ small, as there is also another term in the cost function: , or equvalently, .
Therefore it is clear that when C is getting large, the cost function becomes sensitive to the dataset, and thus sensitive to the outliers:

I understand there is a lack of details in the above description, and I do strongly recommend you to go to have a look at a detailed version that I found online.
Kernel
SVM is powerful to find non-linear boundaries, the secret behind it is called Kernel, all that about is the similarity function:
Previously, our hypothesis was written as
It’s then generalized by replacing , and as , and :
so each f represent a function of features, and there are no differences except the replacements.
We now introdunce the similarity function , the distance between x and some point, or landmark :
for some j = 1, 2, 3, …, m.
We can see and , and the algorithm is now motivated to minimise the distance from x’s to landmarks.
Notice that there is a parameter in the function, σ. This controls the “tolerance” of distance, where an increase in σ makes the kernel less sensitive to , namely the cost of being away to the landmark is now cheaper.

(σ decreases from left to right)
The kernel used above is called the Gaussian Kernel, there are also other types of kernel.
Choosing the landmark
Suppose there are m training examples. For each training example, we place a landmark at exactly the same location, so we end up with m of them, namely:
Therefore there are m kernels in total, for each example where , we have the following representation:
From above we see there are m+1 new features, and our cost function is modified as:
note that n = m since the number of features is the same as of training example.
When Applying SVM…
Choice of parameter C and kernel (similarity function).
The kernel we used above is called Gaussian Kernel, there are also some other types of kernel are available to use (e.g. String kernel, chi-square kernel). A SVM without a kernel is called the linear kernel
Do perform feature scaling before using the Gaussian kernel.
Multi-class classification: Many SVM packages already have built-in multi-class classification functionality. Otherwise, use one-vs-all method. (Train SVMs, one to distinguish from the rest, for ), get . Then pick class i with largest .
Logistic regression VS SVM
These two algorithms are similar, that makes the which-to-use decision hard. Here are some suggestions for it:
Let n and m be the number of features and number of training examples respectively, then
- When n large and m small: Use logistic regression, or SVM without a kernel (linear kernel)
- When n small and m large: Create/add more features, then use logistic regression or linear kernel.
- If n is small, m is intermediate: Use SVM with Gaussian kernel, as the computation is relatively less expensive in this case.
- Also, neural network is likely to work well for most of these settings, but may be slower to train.