Contents: Linear Regression, logistic regression, gradient descent and more.
Week 1
Supervised learning problems are categorized into “regression” and “classification” problems. In a regression problem, we are trying to predict results within a continuous output, meaning that we are trying to map input variables to some continuous function. In a classification problem, we are instead trying to predict results in a discrete output. In other words, we are trying to map input variables into discrete categories.
Regression
We can derive this structure by clustering the data based on relationships among the variables in the data.
To describe the supervised learning problem slightly more formally, our goal is, given a training set, to learn a function h : X → Y so that h(x) is a “good” predictor for the corresponding value of y. For historical reasons, this function h is called a hypothesis.
cost function (Mean squared error MSE):
Our goal is to minimise the cost function, where one possible approach is gradient descent:
where j = 0, …, n and α is learning rate.
We keep update θ’s simultaneously until it converge, such that MSE is minimised.
One of the potential issues with this approach is that it may diverge or converge to local minimum(which is not global minimum).
Week 2
Multivariate Linaer Regression
hypothesis:
Gradient Descent for Multiple Variables:
There are some techiques that could spped up Gradient Descent:
- feature scaling and mean normalization — (working with features)
Debugging gradient descent: Make a plot with number of iterations on the x-axis. Now plot the cost function, J(θ) over the number of iterations of gradient descent. If J(θ) ever increases, then you probably need to decrease α.
Automatic convergence test: Declare convergence if J(θ) decreases by less than E in one iteration, where E is some small value such
as 0.0001. However in practice it’s difficult to choose this threshold value.— (working with learning rate)
On other hand, we can combine multiple features into one. For example, we can combine features a and b into a new feature c by taking their product.
Polynomial Regression
Our hypothesis function need not be linear (a straight line) if that does not fit the data well.
We can change the behavior or curve of our hypothesis function by making it a quadratic, cubic or square root function (or any other form).
For instance, we could do
Week 3
Classification
The classification problem is just like the regression problem, except that the values we now want to predict take on only a finite number of discrete values.
Using Linear regression for classification is often not a very good idea, so we need a new learning method for this kind of problem.
This course will focus on binary classification problem, where y only takes 2 values, say 0 or 1.
Logistic Regression
Our new form uses the Sigmoid Function, also called the Logistic Function:
such that the hypothesis function now satisfies 0 ≤ h ≤ 1, and represents the probability of the output being 1:
Our hypothesis function will create a decision boundary, which is a line that separates the area where y = 0 and where y = 1
Again, like Polynomial Regression, the input to the sigmoid function can be non-linear.(so the decision boundary may be a open/closed curve instead)
Cost function
We cannot use the same cost function that we use for linear regression because the Logistic Function will cause the output to be wavy, causing many local optima. In other words, it will not be a convex function, where there only exists one global minimum.
Instead, our cost function for logistic regression looks like:
And these two functions looks like:
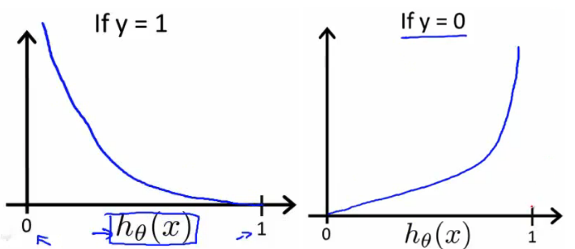
so that these have the following properties:
And actually, we can compress our cost function’s two conditional cases into one case:
Therefore our entire cost function is as follows:
Or, in vectorized implementation:
Gradient Descent
The Gradient Descent procedure for logistic regression looks suprisingly similar with linear regression:
Or, in vectorized implementation:
Advanced optimization techniques
There are more sophisticated, faster ways to optimize θ that can be used instead of gradient descent, eg:
- Conjugate gradient
- BFGS
- L-BFGS
To use these
1 | function [jVal, gradient] = costFunction(theta) |
Then we can use octave’s fminunc() optimization algorithm along with the optimset() function that creates an object containing the options we want to send to fminunc():
1 | options = optimset('GradObj', 'on', 'MaxIter', 100); |
Multiclass Classification
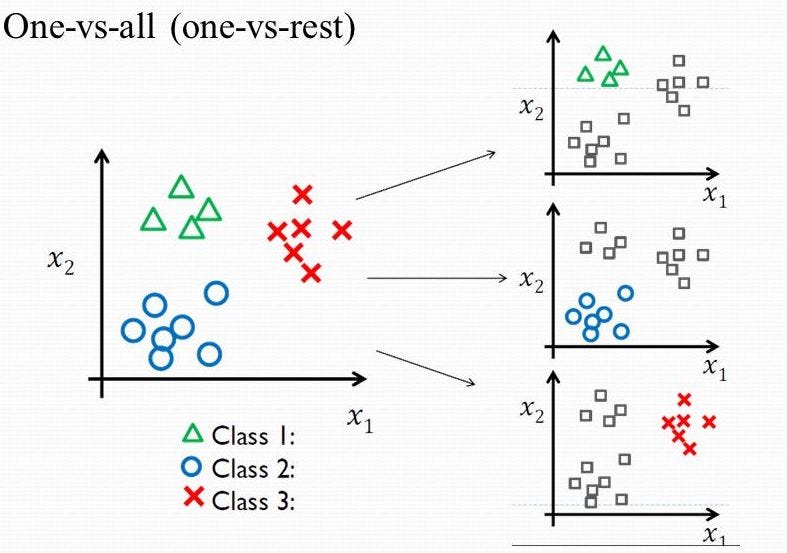
For now we have y = {0,1…n}, one way we can choose is to divide our problem into n+1 binary classification problems; in each one, we choose one class and then lumping all the others into a single second class and then applying binary logistic regression, and then use the hypothesis that returned the highest value (probability)as our prediction, namely pick the class that maximizes the hypothesises, mathematically:
The following image shows an example of 3 classes:
Overfitting
Overfitting is caused by a hypothesis function that fits the available data but does not generalize well to predict new data. This terminology is applied to both linear and logistic regression. There are two main options to address the issue of overfitting:
(1) Reduce the number of features
- Manually select which features to keep.
- Use a model selection algorithm (studied later in the course).
(2)Regularization
- Keep all the features, but reduce the magnitude of parameters
- Regularization works well when we have a lot of slightly useful features.
The way that to reduce the influence of parameters is to modify our cost function by introducing an additonal term:
where λ is the regularization parameter. It determines how much the costs of our theta parameters are inflated.
Or, if we want to eliminate a few parameters instead of all of them, just simply inflate the cost of those parameters. For example:

Suppose we penelize and make really small
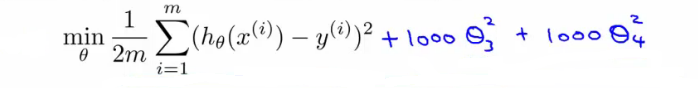
We can apply regularization to both linear regression and logistic regression. We will approach linear regression first:
Regularized Linear Regression
For gradient descent, we will modify our gradient descent function:
The new added term performs our regularization. We can also write the function as:
The first term in the above equation, 1 - αλ/m will always be less than 1. Intuitively you can see it as reducing the value of by some amount on every update. Notice that the second term is now exactly the same as it was before.
For Normal Equation, please refer to the reading page for details.
Regularized Logistic Regression
Regularization for logistic regression is similar to the previous one, where we introduce the exactly same term to the cost function as before:
and then the gradient descent function (procedure) looks exactly the same as the one for linear regression.